If you’ve taken an introductory course in data science, or simply read a lot of articles about it, you’ve probably seen a lot of common techniques being applied over and over again. Some are tried and true, and should survive in the final deliverable of a data science project – a predictive model, or a commercial algorithm, for example. Other techniques are wonderful for use exploring data, but all too often survive to the final product even when they shouldn’t.
Here’s five (possibly surprising) data science techniques that make my list:
1. Linear regression
Kicking the list off is, arguably, the most popular data science technique. Surprised? Linear regression has long been celebrated – it’s simple, it’s fast, it’s interpretable, and everyone suddenly feels more confident in their statements if there’s a line slapped onto a dataset to back them up!
Unfortunately, linear regression usually has very little predictive power. It’s great if all you need to know is if “y generally increases with x” without needing accurate predictions, or if you have too little data to fit with a better model. However, if you have the necessary data volume and quality, and need something more informative/predictive, you’re better off with many other function learning algorithms, such as neural nets or traditional basis expansions, or computing probability distributions on the dataset. Those function expansions utilize the same methods as linear regression, but provide much more robust results. Furthermore, few things in reality are actually linear, as Anscombe’s quartet illustrates:
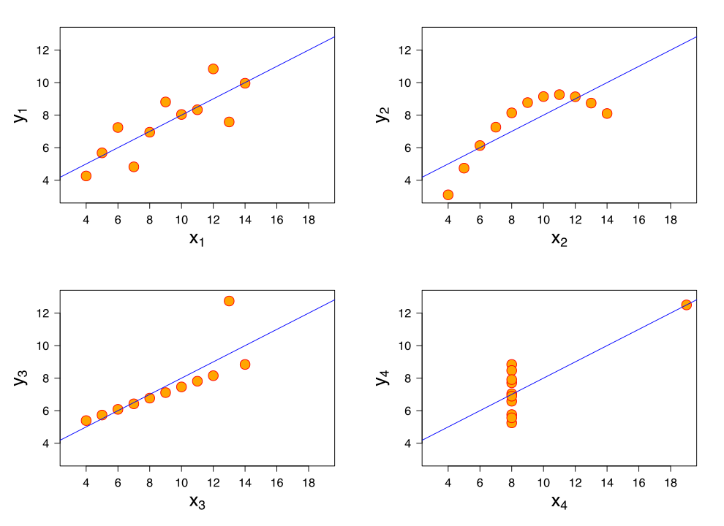 Anscombe, Francis J. (1973) Graphs in statistical analysis. American Statistician, 27, 17–21
Anscombe, Francis J. (1973) Graphs in statistical analysis. American Statistician, 27, 17–21
Anscombe’s quartet shows 4 different data sets that all have the same linear regression. The first data set is a reasonable candidate for linear regression, while the others are clearly not.
2. Logistic regression
Following closely behind is logistic regression, which is modeling the outcome of a set of variables using an s-shape sigmoid function. Like linear regression, it’s fast, and relatively interpretable and simple. However, it requires data variables to be normally distributed and independent. While the central limit theorem suggests that sufficiently complicated variables will tend to be more normally distributed, few things in reality are perfectly normal. A better option would be a neural network. In fact, a single neuron in certain networks can be interpreted as a single logistic regression, so the generalization is readily apparent, and even a small, simple neural net should do better.
3. Bag of words
Bag of words is the practice of treating a sentence as the set of words used to construct it. “Cats like dogs.” “Dogs like cats.” Bag of words can’t tell the difference between these two. “I gave a talk at the conference.” “I delivered a presentation at the convention.” Bag of words can’t tell these two are the same.
The technique obviously loses a tremendous amount of information about synonyms, word ordering, and summarization. Using word vectors – numerical representations of words – helps mitigate some of the problems surrounding synonyms and lexical ambiguity, but more advanced techniques are absolutely necessary for creating more reliable natural language processing (NLP) solutions.
Pre-filtering in a NLP algorithm can include identifying uncommon terms as keywords, but you’ll still want to finish the model off with something more capable, such as recurrent or convolutional neural networks and sentence embeddings.
4. Jaccard index
The Jaccard index measures how much two data sets have in common. It’s the go-to base-line strategy for creating a recommendation engine, as, e.g., movies or music with more properties in common will tend to appeal to someone who likes one of the sets of properties already. Alas, it too ignores nonlinear dependencies, and is, essentially, like bag of words for properties a data set might have.
It’s a great starting place for recommendation engines, but you’d have a bad Netflix experience if they left their engine with just the Jaccard index. Most use cases for the Jaccard index involve identifying the overlap of data subset; for such purposes, try Blu, Levenstein distance, or Dynamic Time Warping.
5. Character-level sentence generation
Sentence generation isn’t really that old, but character-level generation is already over-used and unreliable. If you look up any tutorial on using neural networks to generate sentences, you’ll encounter the famed ‘ChaRNN’ – or, a character recurrent neural network. To skip the fuss of word vectors, ChaRNNs use 26 to 40-dimensional vectors (for English, anyway) to represent characters, and create an algorithm that generates a sentence one. letter. at. a. time. Recurrent networks already struggle to remember what they told you just a moment ago (an unfortunate phenomenon called memory loss), so ChaRNNs almost always end with absurd results, like suggesting you make a delicious meal of crockpot cold water. In a previous blog, I explained what can go wrong when a great algorithm is given bad data; this is what can go wrong when good data is fed to a bad algorithm. If you need a generative NLP algorithm, try an RNN using full word vectors
Do these 5 list-makers have their place? Absolutely! If I didn’t get a sense of what sets shared certain properties or if one variable generally increases with another, I would never have a good entry point from which to build more robust models. This list simply makes the case that they should stay in the exploration stage of a data science project and that their shortcoming should be recognized. Except ChaRNNs. Just avoid those altogether.