Artificial intelligence (AI) won’t be taking over our world, but it will be augmenting human ability in ways that will make our businesses and organizations more efficient for those who adopt deep learning methods. Deep learning represents a class of multi-layered artificial neural networks that have become wildly efficient at many tasks. Gartner estimates that deep learning is poised to become the primary tool set for data scientists, with an estimated 80% of them utilizing it in some form by 2018, and for good reason. Facebook, Google, and other large tech companies have entire departments, curated with the best and brightest minds, that are wholly devoted to deep learning research; and since 2014, deep learning jobs have exploded from virtually zero to 41,000 nationwide. In the current market, those who can adopt deep learning practices the fastest, win the field.
The Current State of Deep Learning
Deep learning is showing amazing promise for data science and AI, primarily because it’s methods get results. Our current state of deep learning ability allows us to perform classification or identification tasks at super-human speed. In this way, they augment and support human actors, such as identifying the most appropriate medical treatments based upon presented symptoms or developing the most stable joint for a bridge. Historically, many of the things we are now doing with deep learning were inaccessible; available only as untested ideas of theorems that could not be practically executed. The rapid rise in computational power and the scaling of data storage, however, has given deep learning a practical boost – bringing many once far off ideas to light.
Deep learning is often described as a “black box” method, something where one can understand the inputs and outputs but not the internal workings. In actuality, deep learning is little more than the mathematics that many scientists utilize on a day to day basis. The reliance on strong math skills has seen increasing numbers of mathematicians and scientists (especially physicists) utilize many of the concepts that are pivotal to deep learning methods in other roles and has also seen these players enter the data science field.
Deep learning differentiates itself from regular machine learning in a key way; optimization vs. learning. Many machine learning methods are built on the idea of hyperparameter optimization – choosing a set of hyperparameters with the goal of optimizing a measure of the algorithm’s performance. Deep learning is attempting to do the same thing in finding that best function, only instead of going through exhaustive hyperparameter tuning procedures, they learn to approximate the natural function that gives us the desired output by approximating the function f to within an arbitrary ε > 0. It’s based on a theory called the Universal Approximation Theorem, and it’s the real learning behind deep learning.
Another key cornerstone of deep learning is the Manifold Hypothesis, which in simplified terms refers to how different types of high-dimensional natural data tend to clump and be shaped differently when visualized in lower dimensions. Deep networks mathematically manipulate and separate data by warping these manfiolds. For instance, let’s take a look at deep learning for natural language processing, which is proving to be one of the most applicable applications of these methods. Take a look at the figure below:
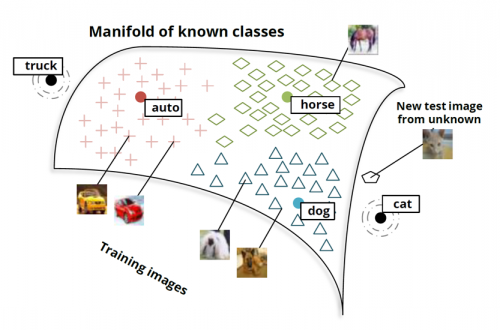
This image roughly represents the manifold that a deep neural network is manipulating when trying to classify images. We train the network on images, and it places those images into mathematical space on the above manifold. While training, the network warps this manifold in order to separate images of different classifications into different regions – this way, when it sees a new image, it can reference that image’s representation in mathematical space, find other similar images, and return a label that represents that sector of the manifold. Now, while this is an overly generalized explanation of what these neural networks are doing, it gives a general idea of just how powerful they are!
The implications of deep learning are impressive; machines are able to recognize objects in video and transcribe speech to text better than humans. Last year Google replaced Google Translate’s “phrase-based” approach of breaking down sentences into words and phrases to be independently translated with neural networks, decreasing error by 60%. Computers are now predicting crop yield better than USDA scientists and can diagnose cancer more frequently and accurately than some of the world’s best doctors.
Current research in deep learning is focusing around reasoning and abstraction, with the latter proving to be the most important – and challenging – AI task moving forward. Contrary to popular belief, modern deep learning architectures take their inspiration from computer science and physics rather than neurology or the biological sciences. More advanced reasoning is being achieved through more complex mathematical interactions and modularization, making these architectures significantly more powerful than traditional machine learning methods.
How Can Deep Learning Help?
Deep Learning is poised to become a tool – something designed to explicitly improve the abilities of our workforce, not a force determined to wreak havoc (as the Press may have you believe). So how can deep learning make an impact?
Even with rudimentary methods, the sheer ability of scaled deep learning algorithms to perform calculations and analyses over millions of words or images gives an organization a significant reduction in turnaround for tasks that might be more challenging for a group of humans. Deep learning can differentiate between biometrics such as faces and fingerprints with significant accuracy, and can blindly identify objects in blurry pictures. More advanced networks, specifically generative networks, can even create new images, sentences, or music in an increasingly human-like manner.
The caveat to all of this potential power is an organization’s ability to scale their algorithms. Deep neural networks can really be powerhouses, but they need the architecture and computational ability to be able to work well. That typically takes a highly skilled team of scientists and engineers working to create integrated deployment environments that are both effective and efficient. According to Gartner, “We will see a blend of professional data integrators and data scientists — who can use this technology (deep learning) to become more efficient.” We’ve seen that in deploying these integrated data teams of data scientists, data integration engineers, dev-ops engineers, and developers – deep learning can be achieved at scale with stunning results.
Ready to get started with deep learning? Here are the three most popular packages used by practitioners in the field:
Keras: A high-level neural networks API written and Python. It can run on top of TensorFlow or Theano. Use Keras for a deep learning library that supports fast prototyping, convolutional networks and recurrent networks, and if you want to work in Python code.
TensorFlow: This popular open-source deep learning framework leverages Google’s infrastructure for scalable training. It provides rich higher level tools for language, image and video understanding.
Theano: A Python library that lets developers define and evaluate mathematical expressions involving multi-dimensional arrays. It uses GPUs and performs efficient symbolic differentiation.