“It is better to be vaguely right than exactly wrong.”– Carveth Read. What does this mean in the world of agile release delivery? Agile does not espouse creating a plan and then doing everything possible to ensure we stick to that original plan. So then how can we plan for a release given these constraints?
Oftentimes when we have a lot of information to help us make a decision we feel obliged to believe the outcome that information provides. After all, more information must mean a more accurate outcome, right? Put another way, when confronted with what is perceived to be only a scant amount of upfront information, we tend to shy away from the outcome it delivers. But being precise only leaves you to be exactly wrong if anything strays from what is expected. It may make more sense to forge down a path that feels vaguely right if expectations are managed properly.
The idea behind a release forecast is rather straightforward: The total amount of work remaining divided by the team velocity indicates when the work is forecast to be completed. Oftentimes this is displayed using a release burnup (see chart).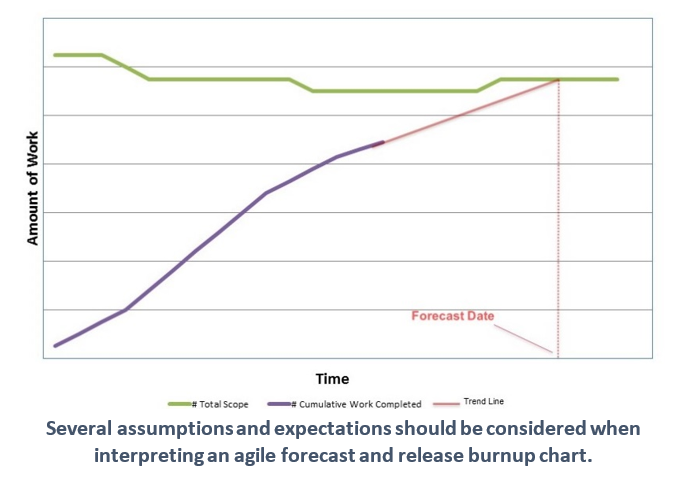
However, to use and interpret the release burnup properly, several assumptions and expectations must be considered – these assumptions, along with what seems like a limited amount of information is what makes all of this seem “vaguely right” and (for some) not precise enough to be useful. However, these assumptions must be considered when tracking release progress:
- The forecast is NOT intended to be precise. The intention of a release forecast is not to be perfect or precise. The forecast serves as a guideline to allow us to have a conversation around what we must do next and how fast we think we can do it.
- Our forecast is only a snapshot of any point in time. Similar to what’s stated above, the forecast is a snapshot of time for right now. Unlike traditionally defined plans, we know this snapshot will change with time. We want it to and will be transparent about it.
- Several factors can directly influence the forecast. We embrace the factors that can influence the forecast by being open and transparent with how they affect it. These include:
- Team velocity. How much a team can accomplish each sprint will obviously influence the forecast. However, teams need to work first on being consistent with their velocity and worry later about “doing more.” Over time, consistency will help our forecasts become more reliable.
- Size of user stories. Release planning requires us to estimate future work, and, undoubtedly, there will be large-sized user stories due to the uncertainty that surrounds that work. However, these large stories are intended to be broken down and understood better as they make their way to the top of the backlog resulting in a more reliable forecast.
- Changes in release scope. The amount of work that comprises the release has a direct impact. If more is added, most likely the forecast date will be pushed back. Obviously, the opposite will hold true if the scope is removed.
- Work not related to the release. Oftentimes teams are saddled with working on more than one project at a time (not ideal, but it happens). The more teams work on non-release related tasks, the less opportunity to complete work related to the release and the further out the forecast.
- The forecast is continuously being updated and is expected to move. Given the factors above, it should be no surprise that the forecast will move frequently. This is not a bad thing since it reflects “real-time” information at any point in time. What is most important is the decisions we make because it moves.
- The forecast should be transparent. This real-time forecast is for everyone to see. It’s meant to be transparent so everyone has the same information at the same time. We want everyone (the team, product owner, clients, stakeholders, etc.) to know the progress so expectations are managed properly and everyone is working and making decisions from the same information.
The information a release forecast conveys is not intended to be precise. Instead, it is intended to be vaguely right. And in the world of uncertainty and complexity, I’ll take vaguely right over exactly wrong anytime.